This flexibility lets you include additional columns in the SELECT list, offering more opportunities for organizing and filtering the result set. Expression_n Expressions that are not encapsulated within an aggregate function and must be included in the GROUP BY Clause at the end of the SQL statement. Aggregate_function This is an aggregate function such as the SUM, COUNT, MIN, MAX, or AVG functions.

Aggregate_expression This is the column or expression that the aggregate_function will be used on. Tables The tables that you wish to retrieve records from. There must be at least one table listed in the FROM clause. These are conditions that must be met for the records to be selected. The expression used to sort the records in the result set. If more than one expression is provided, the values should be comma separated.

ASC sorts the result set in ascending order by expression. This is the default behavior, if no modifier is provider. DESC sorts the result set in descending order by expression. The sum() and total() aggregate functions return the sum of all non-NULL values in the group.

If there are no non-NULL input rows then sum() returns NULL but total() returns 0.0. The non-standard total() function is provided as a convenient way to work around this design problem in the SQL language. There's an additional way to run aggregation over a table. If a query contains table columns only inside aggregate functions, the GROUP BY clause can be omitted, and aggregation by an empty set of keys is assumed. An aggregate function computes a single result from multiple input rows. For example, there are aggregates to compute the count, sum, avg, max and min over a set of rows.

However, aggregate functions take the values of a column from a group of rows and return the result as a single value. Window functions take the values of a column from a group of rows and return a value for each row. An aggregate function can be specified in a window function. A window function cannot be specified in an aggregate function. SUM can be used as either an aggregate function or a window function.

Like most other relational database products, Advanced Server supports aggregate functions. For example, there are aggregates to compute the COUNT, SUM, AVG , MAX , and MIN over a set of rows. Except COUNT function,all the aggregate functions do not consider NULL values. This function returns the value of an expression using column values from a following row.

You specify an integer offset, which designates a row position some number of rows after to the current row. Any column references in the expression argument refer to column values from that later row. Typically, the table contains a time sequence or numeric sequence column that clearly distinguishes the ordering of the rows. This function returns the value of an expression using column values from a preceding row.
You specify an integer offset, which designates a row position some number of rows previous to the current row. Any column references in the expression argument refer to column values from that prior row. Analytic functions are a special category of built-in functions.
Like aggregate functions, they examine the contents of multiple input rows to compute each output value. The HAVING clause is used to further filter the result set groups provided by the GROUP BY clause. HAVING is often used with aggregate functions to filter the result set groups based on an aggregate property.
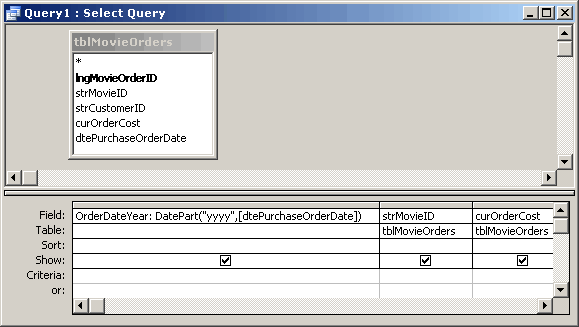
The given query will select only the records from only years where more than 5 movies were released per year. The GROUP BY clause will group records in a result set by identical values in one or more columns. It is often used in combination with aggregate functions to query information of similar records.

The GROUP BY clause can come after FROM or WHERE but must come before any ORDER BY or LIMIT clause. The filter clause extends aggregate functions (sum, avg, count, …) by an additional where clause. The result of the aggregate is built from only the rows that satisfy the additional where clause too. Table 9-50 shows aggregate functions typically used in statistical analysis. In all cases, null is returned if the computation is meaningless, for example when N is zero. In any aggregate function that takes a single argument, that argument can be preceded by the keyword DISTINCT.

In such cases, duplicate elements are filtered before being passed into the aggregate function. For example, the function "count" will return the number of distinct values of column X instead of the total number of non-null values in column X. If the WITH TOTALS modifier is specified, another row will be calculated. This row will have key columns containing default values , and columns of aggregate functions with the values calculated across all the rows (the "total" values). All the expressions in the SELECT, HAVING, and ORDER BY clauses must be calculated based on key expressions or on aggregate functions over non-key expressions . In other words, each column selected from the table must be used either in a key expression or inside an aggregate function, but not both.

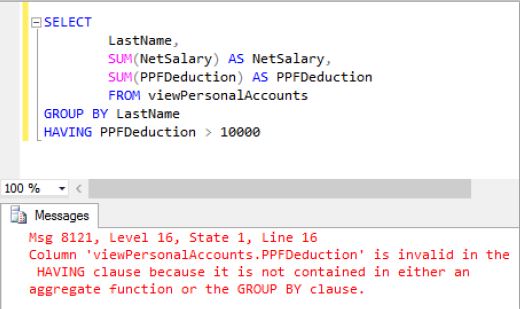
It is not permissible to include column names in a SELECT clause that are not referenced in the GROUP BY clause. The only column names that can be displayed, along with aggregate functions, must be listed in the GROUP BY clause. Since ENAME is not included in the GROUP BYclause, an error message results. The queries use analytic functions with window clauses to compute moving averages of the closing price.

For example, ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING produces an average of the value from a 3-day span, producing a different value for each row. The first row, which has no preceding row, only gets averaged with the row following it. If the table contained more than one stock symbol, the PARTITION BY clause would limit the window for the moving average to only consider the prices for a single stock. Functions for computing a single result from a set of input values. Elasticsearch SQL supports aggregate functions only alongside grouping .

While the first query is not needed, I've used it to show what it will return. I did that because this is what the second query counts. There is a subtle distinction between the WHERE and HAVING clauses. The WHERE clause filters out rows before grouping occurs and aggregate functions are applied. The HAVING clause applies filters on the results after rows have been grouped and aggregate functions have been computed for each group.

The BIT_AND(), BIT_OR(), and BIT_XOR() aggregate functions perform bit operations. Prior to MySQL 8.0, bit functions and operators required BIGINT (64-bit integer) arguments and returned BIGINT values, so they had a maximum range of 64 bits. Non-BIGINT arguments were converted to BIGINT prior to performing the operation and truncation could occur. It's the second part of the error what we are looking for (i.e. or be used in an aggregate function).

In fact, there's a set of aggregate functions that databases offer us. In PostgreSQL count() is one example we've already seen, but there's a lot more. FILTER is a modifier used on an aggregate function to limit the values used in an aggregation. All the columns in the select statement that aren't aggregated should be specified in a GROUP BY clause in the query. Because HBase tables are optimized for single-row lookups rather than full scans, analytic functions using the OVER() clause are not recommended for HBase tables. Although such queries work, their performance is lower than on comparable tables using HDFS data files.
The following sections describe the analytic query clauses and the pure analytic functions provided by Impala. For usage information about aggregate functions in an analytic context, seeImpala Aggregate Functions. The HAVING keyword works exactly like the WHERE keyword, but uses aggregate functions instead of database fields to filter.

The WHERE clause in MySQL is used with SELECT, INSERT, UPDATE, and DELETE queries to filter data from the table or relation. It describes a specific condition when retrieving records from a single table or multiple tables using the JOIN clause. If the specified condition is satisfied, it returns the particular value from the table. The WHERE clause places conditions on the selected columns. The aggregate functions do not include rows that have null values in the columns involved in the calculations; that is, nulls are not handled as if they were zero.

The AVG() aggregate function returns the average value in a column. For instance, to find the average salary for the employees who have less than 5 years of experience, the given query can be used. The COUNT() aggregate function returns the total number of rows that match the specified criteria. For instance, to find the total number of employees who have less than 5 years of experience, the given query can be used.

Aggregate Functions Are Not Allowed In Group By It is therefore possible that another user may be performing a transaction that modifies the data while an aggregate calculation is in process. Aggregate functions don't accept nested aggregate functions or window functions as arguments. Takes two column names or expressions as arguments, the first of these being used as a key and the second as a value, and returns a JSON object containing key-value pairs. Returns NULL if the result contains no rows, or in the event of an error. An error occurs if any key name is NULL or the number of arguments is not equal to 2. Aggregates a result set as a single JSON array whose elements consist of the rows.

The function acts on a column or an expression that evaluates to a single value. For each of these hypothetical-set aggregates, the list of direct arguments given in args must match the number and types of the aggregated arguments given in sorted_args. Unlike most built-in aggregates, these aggregates are not strict, that is they do not drop input rows containing nulls.

Null values sort according to the rule specified in the ORDER BY clause. The GROUP BY statement groups rows that have the same values. This statement is often used with some aggregate function like SUM, AVG, COUNT atc.

Having Clause is basically like the aggregate function with the GROUP BY clause. The HAVING clause is used instead of WHERE with aggregate functions. While the GROUP BY Clause groups rows that have the same values into summary rows. The having clause is used with the where clause in order to find rows with certain conditions. The having clause is always used after the group By clause. Do not use SDOAGGRTYPE as the data type for a column in a table.
Use this type only in calls to spatial aggregate functions. It is actually an example of a user defined aggregate function described below, but Oracle have done all the work for you. This clause can result in different analytic results for rows within the same partition. That is, the set of preceding or following rows considered by the analytic function always come from a single partition. Any MAX(), SUM(), ROW_NUMBER(), and so on apply to each partition independently. Omit the PARTITION BY clause to apply the analytic operation to all the rows in the table.
The OVER clause is required for calls to pure analytic functions such as LEAD(), RANK(), andFIRST_VALUE(). When you include an OVER clause with calls to aggregate functions such as MAX(),COUNT(), or SUM(), they operate as analytic functions. We'll call columns/expressions that are in SELECT without being in an aggregate function, nor in GROUP BY,barecolumns. In other words, if our results include a column that we're not grouping by and we're also not performing any kind of aggregation or calculation on it, that's a bare column.
In this article, we have made a comparison between the WHERE and HAVING clause. Here, we conclude that both clauses work in the same way in filtering the data, except some additional feature makes the HAVING clause more popular. We can efficiently work with aggregate functions in the HAVING clause while WHERE does not allow for aggregate functions. Approximate aggregate functions are scalable in terms of memory usage and time, but produce approximate results instead of exact results.

These functions typically require less memory than exact aggregation functionslike COUNT(DISTINCT ...), but also introduce statistical uncertainty. This makes approximate aggregation appropriate for large data streams for which linear memory usage is impractical, as well as for data that is already approximate. In this query, all rows in the EMPLOYEE table that have the same department codes are grouped together. The aggregate function AVG is calculated for the salary column in each group. The department code and the average departmental salary are displayed for each department. It should be noted that except for count, these functions return a null value when no rows are selected.
In particular, sum of no rows returns null, not zero as one might expect, and array_agg returns null rather than an empty array when there are no input rows. The coalesce function can be used to substitute zero or an empty array for null when necessary. Note that PostgreSQL does not assume a default delimiter.

Also note that like other aggregate functions, you must use the group by clause with string_agg(). Analytic functions are very efficient for Parquet tables. The ORDER BY clause works much like the ORDER BY clause in the outermost block of a query. It defines the order in which rows are evaluated for the entire input set, or for each group produced by a PARTITION BY clause. You can order by one or multiple expressions, and for each expression optionally choose ascending or descending order and whether nulls come first or last in the sort order.

